
To succeed today, you have to get familiar with, and even master, artificial intelligence and machine learning. The companies that are thriving have mastered AI/ML. It has become table stakes very fast.
Jim Cramer hosts a show on CNBC called “Mad Money” in the United States, that really should be called “Math Money.” The reason for this is that he is constantly talking about companies like NVIDIA, Facebook, Amazon, and many others that have been making people mad money on Wall Street because of their mastery of data, math, and algorithms. They will continue to get bigger, cheaper, faster, better, and smarter because of their mastery of artificial intelligence and machine learning (AI/ML). AI/ML is making companies get bigger and people a lot of money.
To better understand this difficult yet important subject, I came across an excellent article written by Dr. Umesh Hodeghatta titled “Challenges of Executing AI/Machine Learning Projects.” The article lays out that there is a lot involved in successfully implementing AI/ML projects.
Dr. Hodeghatta is a leading practitioner and thought leader in the field of AI/Machine Learning. He has authored two technical books: The Infosec Handbook: An Introduction to Information Security and Business Analytics Using R – A Practical Approach. He speaks about AI/ML at conferences all over the world. He has done over twenty webinars on BrightTALK. He has taught AI/ML at universities in both the United States and abroad. He is highly sought after for consulting by Fortune 500 companies. He is a co-founder of Nu-Sigma, an AI/ML solutions provider. So he is the right person to ask questions about AI/ML that many of you have, whether you work as an individual contributor or as a C-Level executive.
Question 1
Can small companies take on AI projects? What is the approach you recommend
they use?
Yes, small companies can take on AI projects. Most of the small companies may have good quality data and may not know how to use it to drive some business problems.
For example, a small solar light manufacturing company with 200-300 people may want to optimize its production line. They may have collected lots of data over a period and may have zeroed in on the bottleneck in their process. But they may not have an IT Technical team who are well versed with data, AI, or Machine Learning. Hence, they are not aware of how the data and AI can be applied to solve the problem in their process.
It is not that we always require huge data for building models or running AI projects. It is the quality of data that matters in most cases. Some small companies may definitely have a good quality of data. Our recommendation to such small companies is to engage companies like NUSA Lab, who can help them deploy AI models to solve their business problems. If they do not have relevant data, we can work with them to collect such data required to train the AI model.
Question 2
What do CEOs need to know before they embark on an AI/ML project so they can succeed?
CEOs need to have the following information before they embark on an AI/ML project:
- Clarity on the problem that is relevant to the business
- Understand the value they expect to gain from AI. Is it optimization, reducing cost, or improve customer satisfaction?
- Understand the reason for executing the AI project, whether to really solve the problem or explore new technology?
Understanding whether AI is a disruptive technology in your industry and how AI can be
leveraged will be the critical skills for successful CEOs both now and in the future
Question 3
What methodology is used in successful AI/ML projects?
NUSA Lab (N-U Sigma U-Square Analytics Lab LLP) has developed a framework that is proven to be effective. Here is our framework:
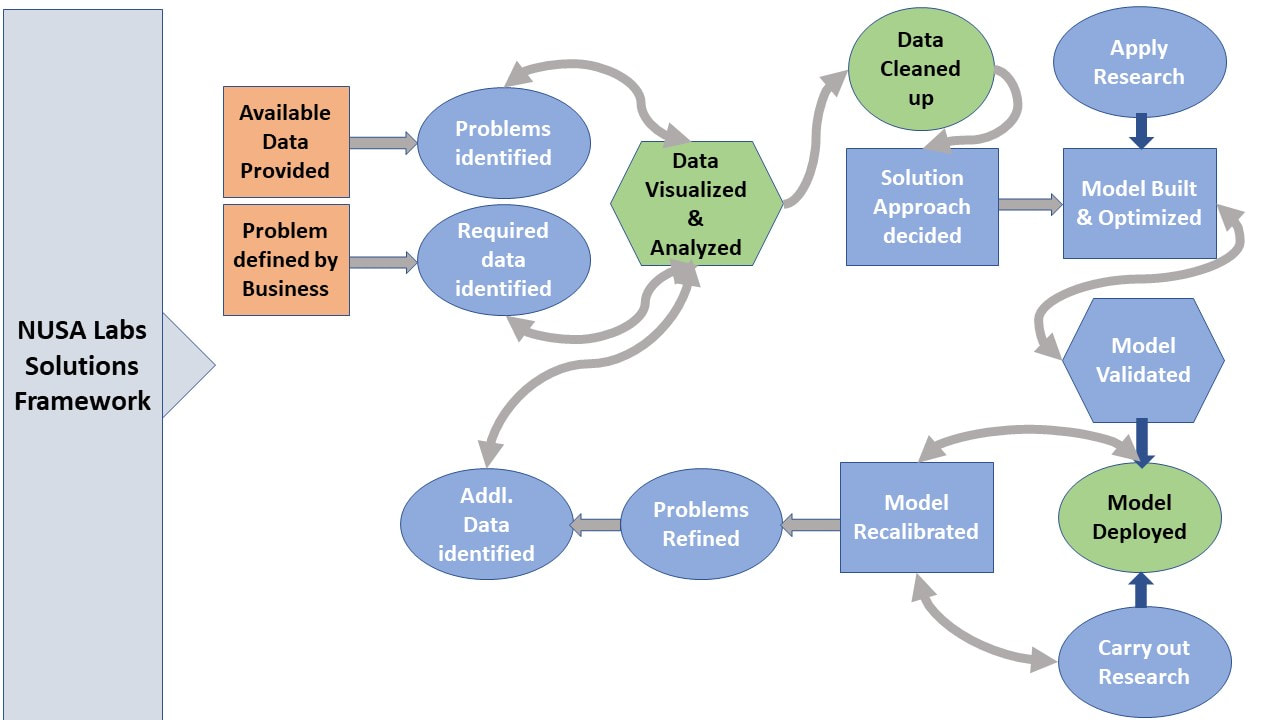
We start with the data and find out the patterns or problems/issues/challenges where data is
available. Else, we start with the business problem/issue/challenge in discussion with the organization. In the second scenario, we suggest the data to be collected if available or partially available. We then analyze the data, understand the data, and clean up the data using various relevant methods.
Once the cleaned data is available, we determine a suitable algorithm to be applied to the data to ensure generalized learning on the data. We build the AI/ML model, optimize it, and validate it. In this process, we apply relevant optimization methods until we get a highly accurate generalized model.
We also apply any relevant recent research which adds value to the project. Then we deploy the model on to production and keep checking the output vs. the expected output. In the process, we carry out the research, and we use that research in recalibrating the model, as and where required. We then redeploy the recalibrated model needed to ensure that the model is still valid despite the changes happening in the ecosystem. In the current world, change is the only constant.
Question 4
What skills do you need to implement an AI/ML project?
The following are the skills typically required to implement an AI/ML project effectively:
- Determining the right business case/problem to be solved
- Allocating the right resources – Data Scientist, Data Plumber, Data Engineer, etc.
- Determining the data needed to train the AI/ML model effectively
- Exploring the data to understand its completeness and correctness
- Determining the appropriate method/algorithm to be used
- Determining appropriate validation methods and optimization methods
- Understanding if the model has appropriately generalized and is not overfit or underfit
- Providing appropriate data stream to the model and eliminating any Bias before deploying the model on the production system and
- Recalibrating the model on a need basis with any changes
Question 5
How do you know whether you have the right data and enough of it that will result
in AI/ML success?
By analyzing the data related to the problem to be solved, we can make out if the right data is collected and available. Normally, we guide the organizations as to what data is required based on the problem/issue being solved. Nowadays, most organizations have a good amount of data, as most of them have moved to digital platforms. However, the quantity of data is secondary. The quality of the data is the most important. There are various ways we can augment the available data. If the problem/issue/challenge makes business sense, and we have quality data, we can always proceed. The relevant data may also be many times possible to be sourced from third-party agencies.
Bonus Questions
Dr. Hodeghatta answered all the questions I sent to him, so I have included them under bonus questions.
Question
Can you explain supervised learning, unsupervised learning, and reinforcement learning? When would you use one over the other, and can you use all three with the data you have?
We use “supervised learning” for predicting a category or a class given that the model is trained based on the data whose categories are already labeled. When we say labeled, somebody, either from their experience or other means, has already classified the record into specific classes. Regression, Classification are some of the areas where we use Supervised Learning. We use unsupervised learning when we do not know the categories/classes to predict.
There is no labeled data to train the model. It is not possible to label them, either because of the lack of evidence or the high cost of labeling. The model itself will identify the data class by categorizing it based on some measure (normally distance measures). Clustering is one of the methods which are part of unsupervised learning. We use reinforcement learning, particularly in those scenarios where there is a reward involved and later steps depend upon the earlier steps.
Question
If a CEO needs to see something quick before providing more funding for an AI/Ml project, what do you suggest an approach CEO should take?
Analyze the data and show the pattern or carry out a small dummy-proof of concept and show the possible value.
Question
How can a CEO determine whether a data scientist is any good? What kind of
questions should he be asking to a data scientist he is talking to?
The CEO should make out the following characteristics of an effective data scientist:
- Should be able to understand the business problem when explained – open mind with good listening skills and understanding capability
- Should be able to suggest the data to be collected based on the discussion with relevant domain experts
- Should be able to determine the right algorithms, optimization methods, and validation methods to be applied
- Should have good interpersonal skills and communication skills to deal effectively with other relevant stakeholders
- Should be able to apply relevant research to the project in hand to deliver a high level of benefit to the company
According to us, I have listed above not the conclusive and exhaustive list but some of the key requirements.
Question
Since you hear AI/ML everywhere, how can a CEO determine whether a problem
lends to automation or machine learning?
Automation is straight forward. You know the rules of the game already. You need to program those rules, test that the rules provide the output as required, and deploy the solution or application. In the case of AI/ML, the patterns or rules are not known. Rules are the one learned by the AI/ML models and are generalized so that the model works effectively on a wide range of
applicable data values.
Question
Can you explain how to mitigate or even eliminate bias in machine learning models and AI systems? Is the problem mainly with the data or algorithms? When you try to mitigate bias, is it possible to overcorrect so that there is a different kind of bias?
A good data scientist always tries to eliminate the AI/ML models’ bias by understanding if the model has generalized well. She/he applies various types of validation over a wide range of possible data points using appropriate evaluation methods to validate that the model has generalized well. A well-generalized model is typically not biased. The experiment is the key to the success of a scientist. A data scientist shall not hesitate to experiment to understand that there is no bias. To do that ideally, she/he should not carry any pre- notions. A detailed webinar is conducted by Dr. Hodeghatta, Umesh, on December 16th, 2020
regarding the bias in AI/ML models.
You can register to learn more about “Bias in AI”:
https://www.brighttalk.com/webinar/bias-in-ai-and-machine-learning-models/?utm_source=social&utm_medium=social&utm_term=data&utm_content=umesh&utm_campaign=Big
Three Book Recommendations on AI/ML for CEOs
Predictive Analytics: The Power to Predict Who Will Click, Buy, Lie, or Die by Eric Siegel
Small Data: The Tiny Clues That Uncover Huge Trends by Martin Lindstrom
Analytics in a Big Data World: The Essential Guide to Data Science and its Applications by Bart Baesens
Dr. Umesh Rao Hodeghatta’s Contact Info:
WebSite: http://www.mytechnospeak.com/
Email: [email protected]
LinkedIn: https://www.linkedin.com/in/uhrao/
I want to thank Dr. Hodeghatta for answering the questions about a very important subject that is changing our world.

I am an author, speaker, executive coach. I guide people thrive on high stakes stage whether it’s for a job interview, career advancement, a sales presentation or a high-stakes speech. I am the author of a practical book on speaking titled Winning Speech Moments: How to Achieve Your Objective with Anyone, Anytime, Anywhere. The main idea of the book is that if you want people to remember your speech and take action, you must create a winning speech moment.
Please download the free speech checklist I created that I always use to create a winning speech for any occasion.
Please contact me if you would like to discuss how you can work with me. If you are interested in inviting me to give a Zoom talk (during the pandemic) on job Interviewing. career development or high-stakes speaking, you can reach me at [email protected] or 732-847-9877.
Note, if you are an author, content producer or interesting and would like me to interview with five questions and then publish it as a blog post and promote it on LinkedIn, Twitter and Facebook, please contact me